
作成日時:2016年08月22日 20時14分37秒
更新日時:2020年05月19日 08時50分12秒
この記事は10年ほど前に投稿されました。内容が古くなっている可能性がありますので更新日時にご注意ください。

※2つの記事を統合しました。
はじめに
Arduinoでグラフィック液晶などを利用する場合に漢字を表示したい。漢字はなくともせめてひらがなだけでも…。と思う時もあるかもしれません。そこで今回はArduinoで文字コードから漢字パターンを取得してみたいと思います。
必要なもの
- SDカードシールド
- FONTX形式のフォントファイル
ネット上にフリーの既存フォントが多く存在していますし、エディタや変換ツールも存在します。
例:ELMソフトウェア FONTXエディタ (Windows用)
ホビーユースでは気にする必要はないでしょうが、他人の作ったフォントを流用したり、変換する場合はフォントファイルのライセンスにご注意ください。
漢字を表示する方法について
Arduinoは基本的には英文をメインに使います。
ですので使う文字といえばASCIIコード前半の文字のみを使う場合が多く。この場合はFONTを使うよりもパターンを書いてしまったほうが早いのですが。やはり日本人としては漢字を、せめてひらがなやカタカナくらいは使いたいと思うことも多いと思います。
正直カタカナだけでいいのであればキャラクタ液晶を使ったほうが手っ取り早いし簡単です。
しかし、何かの図形や画像などを同時に処理をしたいときはフォントを使う必要があります。表示される文字が固定されている場合はそちらも画像で作ってもいいのでしょうが。例えば何かの情報や不定な文字列を表示しようとするとやはりフォントを使う必要があります。
Arduinoで使える文字コードについて
基本的にはUTF-8をメインで使います。
ただし、UTF-8では扱いにくいのでShift-JISやJISコードを使用したいところであります。UTF-8以外を使う場合、メニューを別ファイルにして読み込むか、”\”を付けて文字コードを個別に指定してあげる必要があります。もしくは文字コードを自由に扱える環境を親とし、Arduinoを子として利用し、シリアル通信で送ってやるという方法を取る必要があります。
シリアル通信で漢字を扱う
ハードウェアの前にシリアル通信で漢字を扱ってみたいと思います。
といっても、Arduinoのスケッチの文字コードはUTF-8であり、特に何らかの制限をしているわけではないので。単純にパソコンとの通信でArduinoからのデータ転送時に日本語を表示したいだけであればパソコン側でシリアルモニタではなく端末エミュレータを使用し、文字コードをUTF-8に変更してやるだけでとりあえず表示することはできます。
Serial.begin(9600);
while(!Serial);
Serial.println("Arduinoで日本語表示テスト");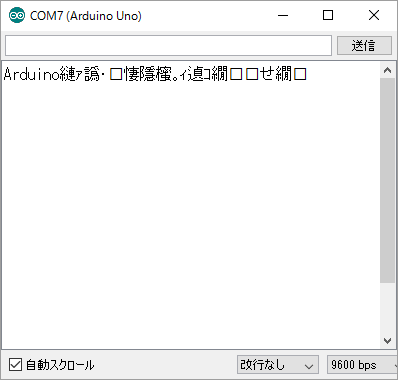 |
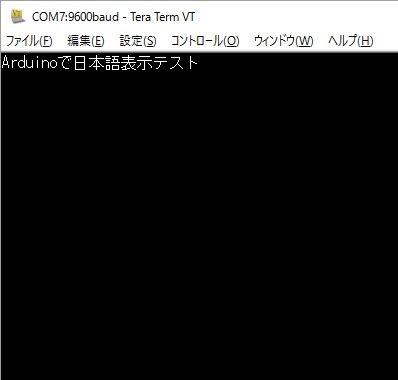 |
| シリアルモニタでの表示 | 端末エミュレータを使用 |
理由は知りませんが。Arduinoのシリアルモニタのエンコードは「Shift_JIS」になっているので、UTF-8のままだと文字化けしてしまいます。というわけでシリアルモニタで漢字を表示してやるならShift_JISで文字コードを転送してしまえばOKという事になります。
文字コードがUTF-8なArduinoスケッチでShift_JISを表示するにはエスケープ文字を使います。
例えば「桜」という漢字のShift_JISコードは「0x8DF7」となるのでこれを1バイトずつエスケープ文字を入れて表記することでShift_JISの文字コードで文字を表示できます。
Serial.println("UTF-8:桜"); // 正常に表示できない
Serial.println("SJIS :\x8D\xF7"); // 正常に表示される。
表示結果:
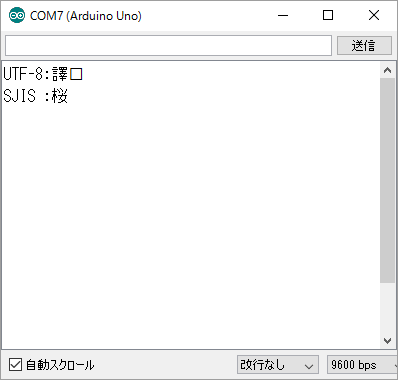
ただし、毎回エスケープ文字を入れてコードを書くのは少々面倒だし、実際のところArduinoIDEのシリアルモニタは性能が良くないので、外部の端末エミュレータを使用した方がよいと思います。
外部の端末エミュレータを使用する場合の注意点は、端末側で繋ぎっぱなしにしているとArduinoIDEからプログラミングの書き込みができなくなるので、必ずプログラムの転送前には接続を切っておく必要があるというところくらいです。標準のシリアルモニタが転送前に毎回閉じるのもこの辺が理由。
使うフォントデータについて
使うフォントデータはFONTX形式を使用します。これは1991年にIBM DOS上の日本語環境改善策として、日本の有志により作成されたフォントドライバで。このソフトウェア自体はDOS/V専用で今となっては無用のものとなりましたが。そのフォントドライバで扱われていたフォントファイルは、形式が単純で軽く、様々なフォントサイズのフォントが扱えるため当時のコンピュータやそれ以下の処理性能しか無いマイコンなどでフォントを扱う場合にもってこいのフォント形式なので最近人気が再燃しているようです。
- 参考資料:FONTXの使いかた)
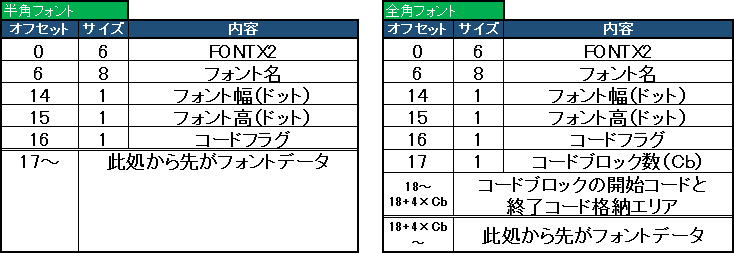
FONTXファイルのフォーマット
基本的に文字コードはShift_JISです。
1バイト目から6バイトがファイルシグネチャ「FONTX2」が入っています。
6バイト目から14バイト目までの8バイトにフォント名が入っています。
この2つはマイコンにてフォントを扱う場合においては気にする必要はないでしょうし、扱うメモリも惜しいですので気にせずに14バイトシークしてしまいましょう。(若しくは最初から削っておくか)
14バイト以降は「フォント幅・フォント高さ・文字コードフラグ」の順で記録されていて各データのデータサイズは1バイトとなっております。
17バイト目はフォントの種類によって違い。半角文字用のフォント(コードフラグ0)の場合はここからフォントイメージが始まります。全角文字用のフォント(フォントフラグ1)の場合は17バイト目にはコードブロックの総数が格納れています。
- コードブロックとは・・・
日本語の文字コードは2バイト文字で65536文字格納することが可能ですが。実際に利用されるのは7000文字程度なので、正直いって殆どの領域が無駄領域となっています。(ただしこれは一般的なフォントファイルはJIS第2水準漢字まで採用していることが多いためであり。Shift_JISの規格上はもう少し文字数は多いです。)そのため、FONTXでは、そのフォントが文字コードのどこからどこまでを収録しているものなのかを格納しておく領域が存在します。これをコードブロックと呼んでおります。
半角フォントの場合はここからフォントデータが始まりますが。全角フォントの場合は先程説明したコードブロックのデータが続いております。2バイトコードですので開始コードと終了コード、計4バイトのデータがコードブロックの総数分記録されています。
つまりこのフォントファイルのヘッダは以下のとおりとなっています。
フォントイメージのについて
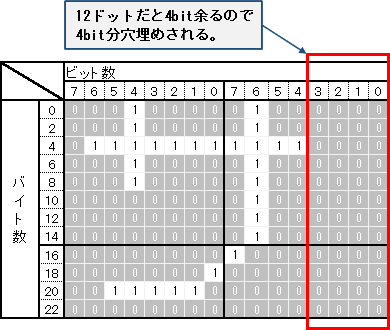
フォントデータはBMP等と同様に横8ドット分が1バイトに収まっていて、例えば12ドットや10ドットのような8の倍数でない場合には8ビット(1バイト)単位で穴埋めされています。
イメージまでのオフセット計算方法
それでは、以上のフォーマットで目的の文字パターンが何処に格納されているのかをどうやって知ればいいのかというと。オフセットを計算すればいいわけですが。半角フォントと全角フォントで計算方法が微妙に違います。
なお、フォントのデータサイズの計算方法は以下のとおりです。(16×16ドットの場合)
- (幅 + 7) ÷ 8 × 高さ
- (16 + 7) ÷ 8 × 16
- 23÷8×16
- 2※×16
- =32バイト
※ 端数切り捨て(int型で計算する)
半角フォントの場合の計算式
- ヘッダサイズ + 文字コード×フォントサイズ
8×16ドットのフォントファイルで、「S」の文字までのオフセットを計算する場合は、
1フォントあたり16バイト、Sの文字コードは0x53(83)ヘッダーサイズは17バイトなので。
- 17+83×16 = 1345バイト
となります。
全角フォントの場合の計算式
- ヘッダサイズ+4×Cb+該当コードまでの文字数×フォントサイズ
8×8ドットのフォントファイルで。「さ」の文字までのオフセットを計算する場合は、
1フォント8バイト、「さ」の文字コードは82B3となります。コードブロックの総数はフォントの収録内容によって違いますが。例えば何時も利用している美咲フォントのサイトにあるFONTX2形式のファイルの場合は92個のブロックに分かれています。
次に該当コードまでの文字数の計算方法ですが。
- フォントブロックの終了コード-フォントブロックの開始コード+1
で1ブロックあたりの文字数を計算して、該当文字コードがその範囲にない場合は次のブロックに進み、該当の文字コードが含まれるまで計算結果を累積していきます。
「さ」の文字は82B3なので、11ブロック目に存在し、10ブロック目までに209文字存在することになり、11ブロック目の開始位置は829Fなので手前に20文字存在することになり、足すと229文字目が「さ」が格納されている文字になります。
これを元に計算すると
- 18+4×92+229×8
- 18+368+1832 = 2218バイト
となります。
つまり上で説明したフォント形式の場合、半角の「S」なら1345バイト目から16バイト抜き出し、全角「さ」なら2218バイト目から8バイト抜き出せば目当ての文字が得られるということです。
コーディング
まずSDカードを使用するので標準ライブラリをインクルードし、defineでフォントファイルのファイル名を指定します。ファイルはSDカード直下に記録しています。
// SDカード用ライブラリ
#include <SPI.h>
#include <SD.h>
// フォントファイルのファイル名を指定
#define FONT_FILEJ "FONTXJ.FNT" // 全角文字用フォントを指定
#define FONT_FILEA "FONTXA.FNT" // 半角文字用フォントを指定
次に上の説明を実現し、パターンを取得する関数を作ります。
関数の詳しい説明はコメントに書いてあるのでそれを読んでください。
////// FONTX形式のフォントファイルからフォントファイルを読み込み。 //////
// 対応フォントはFONTX形式 最小8ドット四方・最大255ドット四方まで対応。
// 最小フォントサイズは実用値、最大フォントサイズは論理値。
//
// 受け渡し用の変数:
// code : 文字コード(符号なしint型)
// *pat : 戻ってきた文字パターンを格納するための配列変数(符号なしchar型)
// 1フォントあたりのバイト数以上を確保すること。
//
// 戻り値: 符号なしlong型。
unsigned long KanjiReadX(unsigned int code , unsigned char *pat) {
// 参考資料:http://www.elm-chan.org/docs/dosv/fontx.html
// オフセット計算用
// ccc = 現在の文字数(Character Count C…?)
// ofset = 最終的なオフセット値(OFfSET)
unsigned long ccc = 0 , ofset = 0;
// フォントファイルを開く
// 文字コードを判別して、文字コードが1バイトの範囲内なら半角コード
// 2バイトの範囲内なら全角コード用のファイルを読み込む。
File fontx_file;
if (code < 0x100) fontx_file = SD.open(FONT_FILEA, FILE_READ);
if (code > 0x100) fontx_file = SD.open(FONT_FILEJ, FILE_READ);
// フォントファイルのファイルタイプとファイル名は不要なので
// その分ファイルをシークしておく
fontx_file.seek(14);
// フォントデータの読み込み。
// Fw = 文字サイズ(横)単位:ピクセル
// Fh = 文字サイズ(縦)単位:ピクセル
// Ft = 文字コード(00ならアスキー 01ならShift_JIS) 最後2つは2バイト文字のみの変数
// Fb = コードブロック数(Fbwはループ用)
uint8_t Fw = fontx_file.read() , Fh = fontx_file.read(), Ft = fontx_file.read() , Fb, Fbw;
// 1文字あたりのデータサイズ(バイト)を計算
uint16_t Fsize = ((Fw + 7) / 8 ) * Fh ;
// コードフラグが0なら英文フォント用のオフセットを書き込む。
if (Ft == 0x00) {
// ヘッダサイズ + 文字コード×1文字あたりのサイズ
if (code < 0x100) ofset = 17 + code * Fsize ;
} else {
// ブロック数のデータは2バイト用フォントにしか無いのでココで取得する。
Fb = Fbw = fontx_file.read();
// フォントオフセット取得用ループ
while (Fbw --) {
// コードブロックからコードの範囲を読み込む
// Cbs = 開始コード(Code Block Start)
// Cbe = 終了コード(Code Block End)
uint16_t Cbs = fontx_file.read() | fontx_file.read() << 8 , Cbe = fontx_file.read() | fontx_file.read() << 8;
// 指示された文字コードがコードブロック内に存在するかどうかを確認
if (code >= Cbs && code <= Cbe) {
// コードブロック内に文字が存在したのなら
// そのコードブロック内で何文字目に存在するのかを取得
ccc += code - Cbs;
// 全体のオフセット値を計算する
// ヘッダサイズ+4バイト×コードブロック数+直前の文字コードまでの文字数×1文字あたりのサイズ
ofset = 18 + 4 * Fb + ccc * Fsize;
// 抜ける
break;
}
// 取得したブロック内に該当文字コードが存在しない場合。
// 存在しなかったブロック内の文字数を計算して次へ。
ccc += Cbe - Cbs + 1 ;
}
}
// ループ用にフォントサイズを退避
uint16_t i = Fsize;
// 指示された文字コードが見つかった場合の処理
if (ofset) {
fontx_file.seek(ofset);
// パターン格納用の変数に漢字パターンを取得し、格納
while (i--) *(pat++) = fontx_file.read();
// 終わったらファイルを閉じる
fontx_file.close();
// フォントデータをリターンして終了
return ((unsigned long)Fw << 24) | ((unsigned long)Fh << 16) | Fsize;
// 戻り値は4バイトデータで、1バイトごとに上から
// 1バイト目 =フォントサイズ(幅)
// 2バイト目 =フォントサイズ(高さ)
// 3・4バイト目=フォントデータのバイト数(2バイト)
// を返す。
}
// 見つからなかった場合はファイルを閉じて0をリターンして終了
fontx_file.close();
return 0 ;
}
この関数の動作は
- 受け取った文字コードの数値により使用フォントを決定
256以下なら半角用フォント、それ以上なら全角用フォントを呼び出す - フォントファイルを14バイトシーク
- ヘッダである文字サイズ縦・横、文字コードを取り出す
- 取り出した文字サイズからデータサイズを計算する
- フォントタイプによって条件を分岐する
半角フォントならオフセットを計算。
全角フォントの場合は、ブロック総数のデータを取得し該当文字が格納されているブロックが見つかるまでブロック内の文字数を控えつつループ、見つかったらオフセットを計算。 - 計算されたオフセット分ファイルをシークする
- そこからフォントのデータサイズ分フォントデータを配列に読み出す
- フォントファイルを閉じる
- 戻り値を返して完了。
戻り値はフォントが見つからない場合は0を返す。
見つかった場合はunsigned longのデータに「フォント幅(1)」「フォント高さ(1)」「データサイズ(2)」を連結させて返す。( )内はバイト数
例えば24×18ドットのフォントの場合はデータサイズは54バイトで「0x18120036」が戻り値となり、これをビット演算で切り出すことで目的の値が取得できる。
という動作になっている。これを使うためには1つのunsigned int(short)型変数と1つのunsigned char型配列、戻り値を格納するunsigned long型が必要となります。
例えば
// 文字コード格納用
unsigned int kanji;
// 漢字パターン格納用
unsigned char pat[32]; // 16x16dot font.
// 戻り値用
unsigned long ret;という変数を確保した場合
- ret = KanjiReadX( kanji , pat );
記述すれば使用することが出来ます。
なお、Arduinoのシリアル通信は1バイトずつ取得できますので、文字コードの受信は以下のとおりに行います。
kanji = (unsigned int)Serial.read() << 8;
if ((kanji >= 0x8000 && kanji <= 0xA000) || kanji >= 0xE000) {
while (!Serial.available());
kanji |= Serial.read();
} else {
kanji >>= 8;
}
最初に8bitシフトして1バイト目を取得します。
そのコードが2バイト文字を扱う範囲にあるかどうかを確認し、2バイト文字の上位バイトだった場合は、2バイト目を続けて取得します。もし1バイト文字と判断された場合は、最初にシフトした8bitを戻して終了します。
戻り値ですが、フォント幅を取得する場合は24bitシフトして0xFFでマスクをして抜き出します。
フォントの高さは16bitシフトしてマスクします。 データサイズを取得する場合はビットシフトは不要で0xFFFFのマスクをかけるだけで取得できます。
実行結果
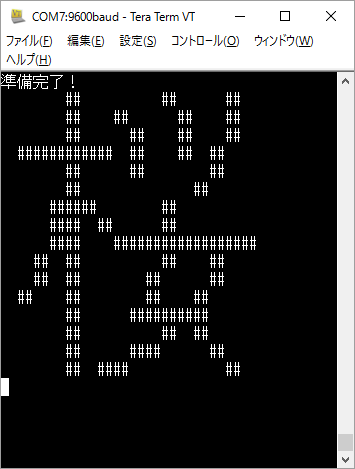
例えば最後に掲載しているサンプルコードを実行して「桜」の文字を送信すると以下のようになるはずです。
(文字コードはShift_JISです。)
終わりに
Arduinoで使う場合は漢字ROMを使う以外では最良の方法だと思います。
Raspberry Piに関しても、多分この方法のほうが早いです。
というわけで今回はフォントファイルから漢字パターンを取得する方法をご紹介しました。
これを使えば8×8ピクセル以外に12×12や16×16、もっと大きなフォントも使えるので例えばカラー液晶などに転送する場合はこっちの方がいいでしょうね。
なお、この文字コードは縦はドット分そのままですが、横が8ドット単位で格納されています。
14ドットなどの場合は2pxの空きとなるので逆に見やすいですが。10pxや12pxの場合はちょっと文字間が開きすぎなので、文字を転送し終えたあと例えば12ドットなら4ドット分戻って次の文字を転送すると穴埋め分をかき消すことができると思います。
それでは。
サンプルコード
// SDカード用ライブラリ
#include <SPI.h>
#include <SD.h>
// フォントファイルのファイル名を指定
#define FONT_FILEJ "FONTXJ.FNT" // 全角文字用フォントを指定
#define FONT_FILEA "FONTXA.FNT" // 半角文字用フォントを指定
void setup() {
// put your setup code here, to run once:
// シリアルポートの初期化 9600bps
Serial.begin(9600);
// シリアル通信が開かれるまで待つ
while (!Serial);
// SDカードの初期化
if (!SD.begin(4)) {
Serial.println("SD card error !");
return;
}
// 準備ができたら「準備完了!」と送信。
// ArduinoIDEのシリアルモニタはShift_JISなのでエスケープ文字をつけて文字コードを送信してやる。
Serial.write("\x8F\x80\x94\xF5\x8A\xAE\x97\xB9\x81\x49\n");
}
////// FONTX形式のフォントファイルからフォントファイルを読み込み。 //////
// 対応フォントはFONTX形式 最小8ドット四方・最大255ドット四方まで対応。
// 最小フォントサイズは実用値、最大フォントサイズは論理値。
//
// 受け渡し用の変数:
// code : 文字コード(符号なしint型)
// *pat : 戻ってきた文字パターンを格納するための配列変数(符号なしchar型)
// 1フォントあたりのバイト数以上を確保すること。
//
// 戻り値: 符号なしlong型。
unsigned long KanjiReadX(unsigned int code , unsigned char *pat) {
// 参考資料:http://www.elm-chan.org/docs/dosv/fontx.html
// オフセット計算用
// ccc = 現在の文字数(Character Count C…?)
// ofset = 最終的なオフセット値(OFfSET)
unsigned long ccc = 0 , ofset = 0;
// フォントファイルを開く
// 文字コードを判別して、文字コードが1バイトの範囲内なら半角コード
// 2バイトの範囲内なら全角コード用のファイルを読み込む。
File fontx_file;
if (code < 0x100) fontx_file = SD.open(FONT_FILEA, FILE_READ);
if (code > 0x100) fontx_file = SD.open(FONT_FILEJ, FILE_READ);
// フォントファイルのファイルタイプとファイル名は不要なので
// その分ファイルをシークしておく
fontx_file.seek(14);
// フォントデータの読み込み。
// Fw = 文字サイズ(横)単位:ピクセル
// Fh = 文字サイズ(縦)単位:ピクセル
// Ft = 文字コード(00ならアスキー 01ならShift_JIS) 最後2つは2バイト文字のみの変数
// Fb = コードブロック数(Fbwはループ用)
uint8_t Fw = fontx_file.read() , Fh = fontx_file.read(), Ft = fontx_file.read() , Fb, Fbw;
// 1文字あたりのデータサイズ(バイト)を計算
uint16_t Fsize = ((Fw + 7) / 8 ) * Fh ;
// コードフラグが0なら英文フォント用のオフセットを書き込む。
if (Ft == 0x00) {
// ヘッダサイズ + 文字コード×1文字あたりのサイズ
if (code < 0x100) ofset = 17 + code * Fsize ;
} else {
// ブロック数のデータは2バイト用フォントにしか無いのでココで取得する。
Fb = Fbw = fontx_file.read();
// フォントオフセット取得用ループ
while (Fbw --) {
// コードブロックからコードの範囲を読み込む
// Cbs = 開始コード(Code Block Start)
// Cbe = 終了コード(Code Block End)
uint16_t Cbs = fontx_file.read() | fontx_file.read() << 8 , Cbe = fontx_file.read() | fontx_file.read() << 8;
// 指示された文字コードがコードブロック内に存在するかどうかを確認
if (code >= Cbs && code <= Cbe) {
// コードブロック内に文字が存在したのなら
// そのコードブロック内で何文字目に存在するのかを取得
ccc += code - Cbs;
// 全体のオフセット値を計算する
// ヘッダサイズ+4バイト×コードブロック数+直前の文字コードまでの文字数×1文字あたりのサイズ
ofset = 18 + 4 * Fb + ccc * Fsize;
// 抜ける
break;
}
// 取得したブロック内に該当文字コードが存在しない場合。
// 存在しなかったブロック内の文字数を計算して次へ。
ccc += Cbe - Cbs + 1 ;
}
}
// ループ用にフォントサイズを退避
uint16_t i = Fsize;
// 指示された文字コードが見つかった場合の処理
if (ofset) {
fontx_file.seek(ofset);
// パターン格納用の変数に漢字パターンを取得し、格納
while (i--) *(pat++) = fontx_file.read();
// 終わったらファイルを閉じる
fontx_file.close();
// フォントデータをリターンして終了
return ((unsigned long)Fw << 24) | ((unsigned long)Fh << 16) | Fsize;
// 戻り値は4バイトデータで、1バイトごとに上から
// 1バイト目 =フォントサイズ(幅)
// 2バイト目 =フォントサイズ(高さ)
// 3・4バイト目=フォントデータのバイト数(2バイト)
// を返す。
}
// 見つからなかった場合はファイルを閉じて0をリターンして終了
fontx_file.close();
return 0 ;
}
void loop() {
// put your main code here, to run repeatedly:
// 文字コード格納用とパターン格納用
static unsigned int kanji;
static unsigned char pat[2 * 16], i;
// 受信データが届くまで待つ
while (!Serial.available());
// 文字コードを検知して1バイト文字なら1バイトだけ抜き出し、
// 2バイト文字なら2バイトをくっつける
kanji = (unsigned int)Serial.read() << 8;
if ((kanji >= 0x8000 && kanji <= 0xA000) || kanji >= 0xE000) {
while (!Serial.available());
kanji |= Serial.read();
} else {
kanji >>= 8;
}
// パターン取得
unsigned long p = KanjiReadX(kanji, pat) ;
// 1バイトに満たない場合は穴埋めされるので
// それに合わせて穴埋めする。
int j = (((p >> 24) & 0xff) + 7) / 8;
// 戻り値からフォントサイズのみ抜き出す。
p &= 0xffff;
// 表示用ループ。
// 改行位置が違う以外は前回のものと同じ。
if (p) {
int x = 0;
while (x < p) {
i = 8;
while (i--) {
if (((pat[x] >> i) & 1) == 0 ) Serial.print(" ");
if (((pat[x] >> i) & 1) == 1 ) Serial.print("##");
}
x++;
if (!(x % j)) Serial.println();
}
// 動いてないのか範囲外のコードなのかわからないので範囲外のコードはエラーを返すようにする。
}else{
char er[32];
sprintf(er,"[ Character code out of range. 0x%04X ]",kanji);
Serial.println(er);}
}
改版履歴
2016年8月22日 2つの記事を統合・加筆しました。
2020年4月8日 誤字修正
[…] FONTXファイルの読み込みはArduinoで作成しましたFONTXライブラリを使いたいと思います。 […]
[…] FONTXファイルの読み込みはArduinoで作成しましたFONTXライブラリを使いたいと思います。 […]